
Engineering Google Docs: A Deep Dive into Building a Real-Time Collaborative Document Editor at Scale
From conflict resolution algorithms to distributed storage - the complete engineering guide to real-time collaborative platforms


Introduction
Building a real-time collaborative document editing system like Google Docs represents one of the most complex challenges in distributed systems engineering. The system must handle millions of users editing documents simultaneously while maintaining consistency, providing sub-second latency, and ensuring zero data loss. This article explores the complete system design, architectural decisions, and engineering trade-offs involved in building such a platform.
Functional Requirements
Core Capabilities
Document Management: Create, read, update, delete documents with rich text formatting, images, tables, and embedded objects
Real-time Collaboration: Multiple users simultaneously editing with instant synchronization of changes
Presence Awareness: Live cursors, selections, and user activity indicators
Version History: Complete audit trail with point-in-time recovery and diff visualization
Offline Support: Seamless offline editing with automatic conflict resolution upon reconnection
Access Control: Granular permissions (owner, editor, commenter, viewer) with sharing via link or email
Comments and Suggestions: Threaded discussions and suggested edits with approval workflows
Search: Full-text search across document content and metadata
Export/Import: Support for multiple formats (PDF, Word, HTML, Plain Text)
Non-Functional Requirements
Performance Requirements
Typing Latency: < 50ms for local character appearance
Remote Update Latency: < 200ms for changes to propagate to other users
Document Load Time: < 2 seconds for 95th percentile
Auto-save Frequency: Every 2-3 seconds or after significant changes
Search Response Time: < 500ms for full-text search
Scale Requirements
Users: 500M+ monthly active users
Concurrent Editors: Support 1000+ simultaneous editors per document
Document Size: Up to 100MB with 1M+ characters
Storage: Petabytes of document data
Operations: 1M+ operations per second globally
Reliability Requirements
Availability: 99.99% uptime (52 minutes downtime/year)
Durability: 99.999999999% (11 nines) data durability
Consistency: Strong eventual consistency with conflict resolution
Disaster Recovery: RPO < 1 minute, RTO < 5 minutes
High-Level Architecture
The system follows a microservices architecture with clear separation of concerns:
Client Layer
Web Application: React-based SPA with rich text editor
Mobile Apps: Native iOS/Android applications
Desktop Apps: Electron-based desktop clients
API Clients: REST and GraphQL APIs for third-party integrations
Edge Layer
CDN: Global content delivery for static assets and document attachments
Edge Servers: Geographically distributed for reduced latency
DDoS Protection: Traffic filtering and rate limiting at edge
API Gateway Layer
Load Balancers: Geographic and application-level load distribution
API Gateway: Request routing, authentication, rate limiting
Protocol Translation: WebSocket upgrade for real-time connections
Service Mesh: Inter-service communication with circuit breakers
Application Services Layer - Detailed Architecture
Document Service
Core Responsibilities: The Document Service acts as the primary gateway for all document-related operations, serving as the source of truth for document metadata and orchestrating interactions with other services.
Internal Architecture:
API Layer: RESTful endpoints for CRUD operations, GraphQL for complex queries
Business Logic Layer: Document validation, schema enforcement, lifecycle management
Data Access Layer: Abstract interface for multiple storage backends
Event Publisher: Publishes document events to message queue for downstream services
Storage Strategy:
Metadata Storage: PostgreSQL with read replicas
Primary table: documents (id, owner_id, title, created_at, updated_at, size, status)
Indexing strategy: B-tree on id, composite index on (owner_id, updated_at)
Partitioning: Range partitioning by created_at for archive management
Content Storage: Hybrid approach
Small documents (<1MB): Stored inline in PostgreSQL JSONB columns
Large documents: S3-compatible object storage with CDN distribution
Temporary edits: Redis with 24-hour TTL
Document Structure Management:
Schema Definition: JSON Schema for document structure validation
Document Tree: Maintains hierarchical structure of document elements
Element Registry: Tracks all referenceable elements (paragraphs, images, tables)
Link Management: Bidirectional reference tracking for embedded objects
Performance Optimizations:
Lazy Loading: Documents loaded in chunks (initial 50KB, then on-demand)
Compression: Gzip compression for documents > 100KB
Caching Strategy:
L1 Cache: In-memory LRU cache (application level) - 100 hot documents
L2 Cache: Redis cluster - 10,000 recently accessed documents
L3 Cache: CDN for read-only document versions
Write Coalescing: Batch metadata updates every 100ms
Lifecycle Management:
States: draft → active → archived → deleted → purged
Soft Deletion: 30-day retention with recovery option
Archive Policy: Auto-archive after 180 days of inactivity
Purge Strategy: Hard delete after 1 year in deleted state
Collaboration Service
Core Architecture: The Collaboration Service maintains the real-time editing infrastructure, managing WebSocket connections, coordinating concurrent edits, and serving as the primary writer to object storage for active documents.
Connection Management:
WebSocket Gateway: HAProxy with sticky sessions for connection affinity
Connection Pool: Each server handles 10,000 concurrent WebSocket connections
Session State: Stored in Redis with automatic failover
Heartbeat Mechanism: 30-second ping/pong with automatic reconnection
Document State Management: The Collaboration Service is responsible for maintaining the authoritative document state for all active editing sessions:
In-Memory State: Each active document maintains full state in memory
State Synchronization: Redis used for state sharing across service instances
Document Locking: Distributed locks prevent concurrent writes to S3
State Recovery: Can rebuild from S3 + operation log on service restart
Object Storage Integration (Primary Responsibility): The Collaboration Service acts as the primary writer to object storage for all active documents:
Save Pipeline to S3:
Trigger Conditions:
- Timer-based: Every 5 seconds for active documents
- Operation-based: After 100 operations accumulated
- Size-based: When changes exceed 1MB
- Explicit: User-triggered save action
- Idle: After 30 seconds of no activity
Save Process:
1. Check if document has unsaved changes (dirty flag)
2. Acquire distributed lock using Redis Redlock algorithm
3. Serialize current document state from memory
4. Apply compression (Brotli for text, achieving 30-50% reduction)
5. Calculate SHA-256 checksum for integrity
6. Upload to S3 with parallel multipart upload for large documents:
- Primary: s3://documents-hot-{region}/{doc_id}/current/content.json
- Version: s3://documents-hot-{region}/{doc_id}/v{revision}/content.json
- Backup: s3://documents-backup-{region}/{doc_id}/current/content.json
7. Update metadata in Redis and PostgreSQL
8. Clear dirty flag and release lock
9. Publish "document.saved" event to Kafka
S3 Bucket Configuration:
- Versioning: Enabled for all document buckets
- Replication: Cross-region replication to backup region
- Lifecycle: Move old versions to S3-IA after 30 days
- Encryption: AES-256 server-side encryption
- Access: IAM roles with minimal required permissionsOperation Processing Pipeline:
Reception Layer: WebSocket frames decoded and validated
Transformation Engine: OT/CRDT processing based on document configuration
State Update: Apply to in-memory document state
Persistence Trigger: Mark document as dirty for next save cycle
Distribution Layer: Fan-out to all connected clients
Operation Log: Async write to Cassandra for durability
OT Implementation Details:
Operation Types: insert, delete, format, embed, annotate
Transformation Matrix: Pre-computed transformations for operation pairs
Revision Tracking: Vector clocks for causality, lamport timestamps for ordering
Acknowledgment Protocol: Three-way handshake for operation confirmation
CRDT Implementation Details:
Data Structure: RGA (Replicated Growable Array) for text
Unique Identifiers: (site_id, counter, position) tuples
Tombstone Management: Garbage collection after all peers acknowledge
Merge Strategy: Three-way merge with automatic conflict resolution
Session Management:
Session Store: Redis Cluster with Sentinel for HA
Session Data:
Active users list with metadata
Document state checksum
Operation buffer (last 1000 operations)
Cursor positions and selections
Last save timestamp and revision
Session Recovery: Automatic state reconstruction from S3 + operation log
Load Balancing: Consistent hashing for session distribution
Failure Handling:
S3 Write Failures: Retry with exponential backoff, fallback to backup region
Memory Pressure: Offload inactive documents to Redis, reload on demand
Service Crash: Recover document state from S3, replay recent operations from Cassandra
Network Partition: Continue operating with local state, reconcile when healed
Performance Optimizations:
Write Batching: Combine multiple saves within 100ms window
Compression Cache: Cache compressed versions for frequently saved documents
Parallel Uploads: Use S3 multipart upload for documents > 5MB
Connection Pooling: Reuse S3 connections across saves
Async Processing: Non-blocking I/O for all storage operations
Monitoring and Metrics:
Save Latency: P50, P95, P99 for S3 writes
Save Frequency: Documents saved per second
Failure Rate: S3 write failures and retries
Document Size: Distribution of document sizes
Active Sessions: Current number of editing sessions
Scalability Measures:
Horizontal Scaling: Auto-scaling based on connection count and CPU
Sharding: Documents distributed across instances using consistent hashing
Regional Deployment: Collaboration servers in 15+ regions
Edge Optimization: Initial WebSocket connection at edge, then routed to regional server
Presence Service
Architecture Overview: Ephemeral service managing real-time user presence with automatic cleanup and minimal latency.
Data Model:
Presence Object: {user_id, document_id, cursor_position, selection_range, status, last_seen, color}
Storage: Redis Sorted Sets with score as timestamp
TTL Management: 60-second expiry with 30-second heartbeat
Presence Broadcasting:
Pub/Sub Channels: Redis Pub/Sub per document
Update Frequency: Throttled to max 10 updates/second per user
Delta Updates: Only send changed fields
Batch Broadcasting: Combine multiple presence updates in 100ms windows
Cursor Synchronization:
Position Tracking: Character offset with Unicode normalization
Transform Pipeline: Cursor positions transformed with document operations
Collision Detection: Multiple cursors at same position handled with offset
Smooth Animation: Client-side interpolation for cursor movement
Selection Management:
Range Representation: (start_offset, end_offset, direction)
Overlap Handling: Visual layering for overlapping selections
Color Assignment: Consistent colors using hash(user_id) % palette_size
Performance: Virtual rendering for large selections
Cleanup Mechanisms:
Heartbeat Monitoring: Remove users after 2 missed heartbeats
Graceful Disconnect: Immediate removal on explicit disconnect
Zombie Detection: Periodic sweep for stale presence data
Reconnection Handling: Preserve presence across brief disconnects
Permission Service
Permission Model:
Levels: owner → editor → commenter → viewer
Granularity: Document, folder, organization levels
Inheritance: Hierarchical with override capability
Special Permissions: can_share, can_download, can_print, can_copy
Storage Architecture:
Primary Store: PostgreSQL for ACID compliance
permissions table: (document_id, user_id, permission_level, granted_by, granted_at)
Composite primary key: (document_id, user_id)
Cache Layer: Redis with 5-minute TTL
Audit Log: Append-only table in PostgreSQL, archived to S3 after 90 days
Access Control Implementation:
RBAC Engine: Role-based access with custom roles
ABAC Support: Attribute-based for enterprise (department, project, etc.)
Token System: JWT with embedded permissions for stateless verification
Policy Engine: Declarative policies using Open Policy Agent (OPA)
Sharing Mechanisms:
Link Sharing:
UUID-based shareable links with optional expiry
Password protection with bcrypt hashing
View count and access tracking
Email Sharing:
Invitation queue with retry logic
Batch processing for large recipient lists
Domain whitelist/blacklist support
Performance Optimizations:
Permission Caching: Multi-level cache with eager invalidation
Batch Checking: Check multiple permissions in single query
Denormalization: Materialized view for user's accessible documents
Bloom Filters: Quick negative permission checks
Security Measures:
Audit Logging: Every permission check logged with context
Anomaly Detection: ML-based unusual access pattern detection
Rate Limiting: Per-user and per-document limits
Encryption: Permission tokens encrypted at rest
Version Service
Version Strategy:
Snapshot Frequency: Every 100 operations or 5 minutes
Operation Log: All operations between snapshots
Retention Policy:
Last 100 versions always kept
Daily snapshots for 30 days
Weekly snapshots for 1 year
Monthly snapshots indefinitely
Storage Architecture:
Snapshot Storage:
S3-compatible object storage with lifecycle policies
Compression: Brotli for text, preserved for binary
Deduplication: Content-addressable storage with SHA-256
Operation Log:
Cassandra for high write throughput
Partition key: (document_id, day_bucket)
Clustering key: (timestamp, operation_id)
TTL: 90 days for operation details
Diff Generation:
Algorithm: Myers diff algorithm for line-by-line comparison
Optimization: Pre-computed diffs for adjacent versions
Visualization: Three-way diff for merge conflicts
Performance: Async diff generation with caching
Recovery Mechanisms:
Point-in-Time Recovery: Rebuild document to any version
Selective Rollback: Undo specific changes while preserving others
Branch Support: Fork document at any version
Merge Capabilities: Three-way merge with conflict resolution
Data Model:
Version Metadata: {version_id, document_id, created_at, created_by, operation_count, size, checksum}
Version Graph: DAG structure for branching/merging
Change Summary: Automated summary of changes per version
Optimization Strategies:
Delta Encoding: Store only differences between versions
Compression Pipeline: Progressive compression for older versions
Lazy Loading: Load version content only when accessed
Prefetching: Predictive loading of likely-to-access versions
Search Service
Search Architecture:
Primary Index: Elasticsearch cluster with 3 master, 10 data nodes
Secondary Index: PostgreSQL full-text search for simple queries
Real-time Indexing: Kafka consumer for document changes
Batch Indexing: Daily reindex for consistency
Index Design:
Document Index:
Fields: title, content, author, tags, created_date, modified_date
Analyzers: Language-specific with stemming and synonyms
Custom tokenizers for code blocks and URLs
Metadata Index:
Structured data for filtering
Nested objects for comments and revision data
Suggest Index:
Completion suggester for autocomplete
Phrase suggester for "did you mean"
Search Features:
Query Types:
Full-text with relevance scoring
Phrase search with proximity matching
Wildcard and regex patterns
Fuzzy matching for typos
Filtering:
Date ranges, author, document type
Access-controlled results
Custom metadata filters
Ranking:
BM25 algorithm with tuning
Boost recent documents
Personalization based on user history
Performance Optimizations:
Query Cache: Redis cache for frequent queries (1-hour TTL)
Aggregation Cache: Pre-computed facets for common filters
Shard Strategy: 5 shards per index with 2 replicas
Circuit Breaker: Prevent memory-intensive queries
Query Optimization: Query rewriting for performance
Indexing Pipeline:
Document change event received from Kafka
Content extraction and preprocessing
Language detection and analysis
Asynchronous indexing with retry logic
Cache invalidation
Search warming for popular documents
Search Analytics:
Query Logging: All searches logged for analysis
Click-through Tracking: Measure search relevance
Popular Searches: Trending queries dashboard
Zero Results: Track and improve failed searches
Notification Service
Notification Architecture:
Message Queue: Amazon SQS/Google Pub/Sub for reliability
Priority Queues: High (mentions), Medium (shares), Low (updates)
Delivery Channels: WebSocket, Push, Email, SMS
Template Engine: Handlebars for multi-language support
Event Processing:
Event Types:
Real-time: mentions, comments, active editing
Delayed: daily summary, weekly reports
Triggered: permission changes, version milestones
Event Router:
Rule engine for routing logic
User preference checking
Deduplication within time windows
Rate limiting per user per channel
Delivery Mechanisms:
WebSocket Delivery:
Direct push to connected clients
Fallback to queue if disconnected
Guaranteed delivery with acknowledgment
Email Delivery:
SendGrid/SES integration
Batch processing for efficiency
Template rendering with personalization
Bounce and complaint handling
Push Notifications:
FCM for Android, APNS for iOS
Token management with automatic cleanup
Rich notifications with actions
User Preference Management:
Preference Store: PostgreSQL with Redis cache
Granularity: Global, per-document, per-event-type
Quiet Hours: Time-zone aware delivery scheduling
Batching Rules: Combine notifications within time window
Unsubscribe: One-click with token verification
Performance and Reliability:
Retry Logic: Exponential backoff with max attempts
Dead Letter Queue: Failed notifications for manual review
Idempotency: Unique notification IDs prevent duplicates
Circuit Breaker: Disable failing channels temporarily
Monitoring: Delivery rates, latency, failure tracking
Analytics and Optimization:
Engagement Tracking: Open rates, click rates, dismissal rates
A/B Testing: Template and timing optimization
Feedback Loop: Unsubscribe and spam signals
Smart Timing: ML-based optimal delivery time prediction
Real-time Infrastructure Layer
WebSocket Servers
Maintains persistent connections with clients, handles connection pooling and multiplexing, provides automatic reconnection with state recovery, and implements backpressure mechanisms.
Message Queue System
Uses Apache Kafka or AWS Kinesis for operation streaming, provides ordered message delivery per document, handles replay for crash recovery, and enables event sourcing architecture.
Pub/Sub System
Redis Pub/Sub or Google Cloud Pub/Sub for presence updates, broadcasts cursor movements and selections, and provides room-based subscriptions per document.
Conflict Resolution Strategies
Operational Transformation (OT) Approach
Operational Transformation is the traditional approach used by Google Docs. It provides a mathematical framework for transforming concurrent operations to maintain consistency.
Architecture for OT:
Centralized transformation server per document
Linear operation history with revision numbers
Server as single source of truth
Client-server operation exchange protocol
Advantages:
Preserves user intent accurately
Mature and well-tested approach
Efficient for centralized architecture
Predictable conflict resolution
Challenges:
Requires central coordination
Complex transformation matrices
Difficult to scale horizontally
Higher latency for global users
CRDT (Conflict-free Replicated Data Type) Approach
CRDTs enable decentralized collaboration with automatic conflict resolution through commutative operations.
Architecture for CRDT:
Peer-to-peer operation exchange possible
Each character/element has unique identifier
Tombstone marking for deletions
Vector clocks for causality tracking
Advantages:
No central coordination required
Automatic conflict resolution
Better offline support
Horizontally scalable
Lower latency for edge cases
Challenges:
Higher memory overhead (30-50% more)
Garbage collection complexity
Less intuitive conflict resolution
Metadata grows with document history
Hybrid Approach
Many modern systems use a hybrid approach combining benefits of both:
CRDT for local operations and offline mode
OT for server-side coordination and optimization
Periodic snapshot consolidation
Garbage collection for CRDT metadata
End-to-End Flow Walkthroughs
Flow 1: Document Creation and Initial Load
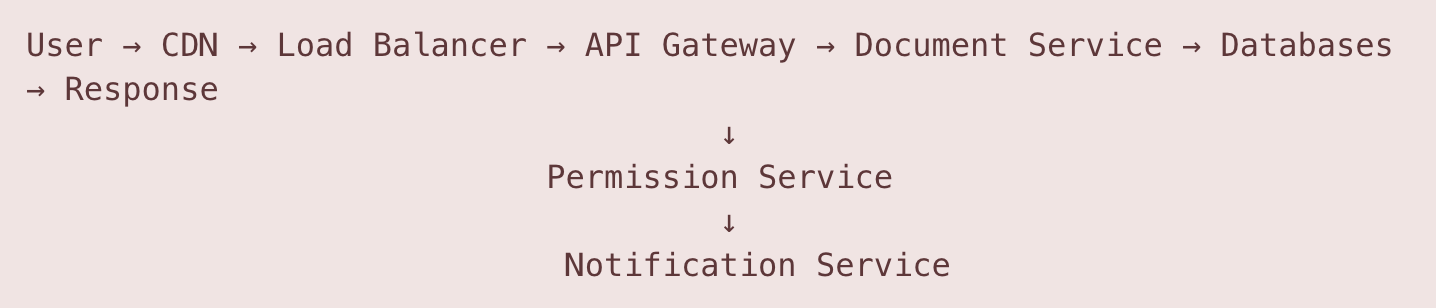
Detailed Steps:
User initiates document creation
Browser sends HTTPS POST request to create document
Request includes: title, template_id (optional), folder_id
CDN and Load Balancer (CloudFlare/AWS ALB)
Request bypasses CDN (POST request)
Geographic load balancer routes to nearest region
Application load balancer selects healthy API Gateway instance
API Gateway (Kong/AWS API Gateway)
Validates JWT token from Authorization header
Rate limiting check (100 documents/hour per user)
Request ID generated for distributed tracing
Routes to Document Service
Document Service Processing
Generates UUID for document_id
Creates document metadata entry in PostgreSQL
Initializes document structure in Redis (temporary)
Publishes "document.created" event to Kafka
Permission Service Integration
Automatically called by Document Service
Creates owner permission entry in PostgreSQL
Adds entry to user's document list (denormalized table)
Caches permission in Redis (5-minute TTL)
Storage Operations
For empty document: Only metadata stored
For template: Template content copied from S3
Document structure saved to PostgreSQL JSONB column
Notification Service
Consumes "document.created" event from Kafka
Checks if user has collaborators to notify
Queues notifications if sharing enabled
Response Path
Document Service returns document object with metadata
API Gateway adds CORS headers
Response cached in CDN for subsequent reads
Client receives response and redirects to editor
Tools & Technologies:
Load Balancer: AWS ALB/Google Cloud Load Balancing
API Gateway: Kong/AWS API Gateway
Databases: PostgreSQL (metadata), Redis (cache)
Message Queue: Apache Kafka
Object Storage: AWS S3/Google Cloud Storage
Flow 2: Real-time Collaborative Editing
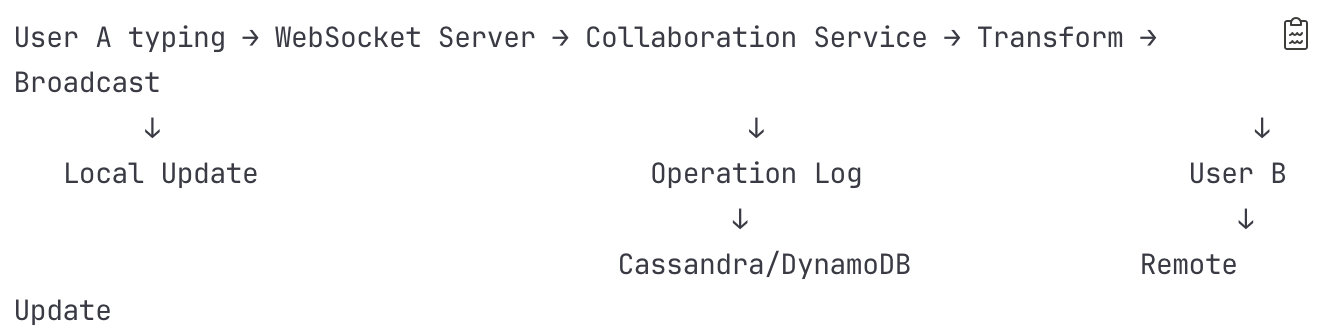
Detailed Steps:
User A Types Character
Keystroke captured by browser editor
Operation created: {type: "insert", position: 245, content: "a", revision: 42}
Applied optimistically to local document
Sent via WebSocket connection
WebSocket Server (Node.js cluster with Socket.io)
HAProxy maintains sticky session
Connection verified against session in Redis
Operation added to receive buffer
Acknowledgment sent immediately
Collaboration Service Processing
Operation validated (schema, permissions)
Current document revision checked in Redis
Operation queued for transformation
Operational Transformation Engine
Retrieves concurrent operations from buffer
Applies transformation algorithm:
if (op1.position <= op2.position) {
op2.position += op1.content.length
}Updates operation with new revision number
Maintains operation history in memory
Persistence Layer
Operation logged to Cassandra
Partition key: (document_id, day_bucket)
Clustering key: (timestamp, operation_id)
Asynchronous write with write-ahead log
Replication factor: 3 across availability zones
Broadcasting to Collaborators
Collaboration Service queries active sessions from Redis
Gets list of connected users for document
Operation sent to Message Queue (Redis Pub/Sub)
Each WebSocket server subscribed to document channel
User B Receives Update
WebSocket server receives from Pub/Sub
Finds User B's connection in local map
Sends operation via WebSocket
Client applies operation to document
Presence Updates
Cursor position updated in Redis Sorted Set
Presence broadcast throttled (max 10/second)
Other users see cursor move in real-time
Conflict Resolution Example:
User A: Insert "Hello" at position 10 (revision 42)
User B: Insert "World" at position 10 (revision 42)
Server receives A first:
- A's operation applied as-is
- B's operation transformed: position becomes 15
- Both users converge to "HelloWorld" at position 10Tools & Technologies:
WebSocket: Socket.io with Node.js
Load Balancer: HAProxy with sticky sessions
Cache: Redis Cluster
Operation Log: Apache Cassandra
Pub/Sub: Redis Pub/Sub
Monitoring: Prometheus + Grafana
Flow 3: Document Search Operation

Detailed Steps:
User Enters Search Query
Query: "meeting notes from last week"
Includes filters: date_range, document_type
Client sends GET request to /api/search
API Gateway Processing
JWT validation and user context extraction
Query parameter sanitization
Rate limiting (100 searches/minute)
Search Service Query Analysis
Natural language processing:
"last week" → date_range: [now-7d, now]
"meeting notes" → document_type: "notes", tags: ["meeting"]
Query expansion with synonyms
User's permission context loaded from cache
Elasticsearch Query Construction
json
{
"bool": {
"must": [
{"match": {"content": "meeting notes"}},
{"terms": {"accessible_by": [user_id, team_ids]}}
],
"filter": [
{"range": {"updated_at": {"gte": "now-7d"}}}
]
}
}Permission Filtering
Search Service queries Permission Service
Gets list of accessible document IDs
Adds filter to Elasticsearch query
Uses Bloom filter for quick exclusions
Elasticsearch Execution
Query routed to relevant shards
Each shard executes query in parallel
Results aggregated and scored
Top 20 results returned
Metadata Enrichment
Document IDs sent to PostgreSQL
Batch query for metadata (title, author, last_modified)
Join with collaboration data (recent editors)
Cache results in Redis
Response Assembly
Results formatted with highlights
Facets calculated (document types, dates)
Suggestions generated ("did you mean...")
Response compressed and sent
Search Indexing Pipeline (Async):

Tools & Technologies:
Search Engine: Elasticsearch 8.x cluster
NLP: Apache OpenNLP for query parsing
Message Queue: Apache Kafka
Cache: Redis for query cache
Database: PostgreSQL for metadata
Flow 4: Auto-save and Version Creation

Detailed Steps:
Auto-save Trigger (every 2 seconds of inactivity)
Client detects no typing for 2 seconds
Collects uncommitted operations from buffer
Calculates document checksum
Sends batch to server
Client-side Processing
Operations compressed with Brotli
Batch of operations prepared
Retry logic initialized (3 attempts)
Request sent via WebSocket or HTTPS POST
API Gateway
Request authenticated and authorized
Routed to Collaboration Service
Idempotency check using request ID
Collaboration Service Processing
Document locked in Redis (distributed lock)
Operations validated against current version
Operations applied to in-memory document state
Triggers persistence pipeline
Multi-Tier Persistence Strategy Tier 1: Operation Log (Immediate)
Every operation saved to Cassandra
Enables replay and recovery
High write throughput optimized
Tier 2: Document State (Every 5 seconds)
Collaboration Service maintains dirty flag
When triggered, current document serialized
Saved to S3 as current version:
Primary Location:
Bucket: documents-hot-{region}
Key: {doc_id}/current/document.json
Backup Location (async):
Bucket: documents-backup-{region}
Key: {doc_id}/current/document.jsonTier 3: Snapshots (Every 100 operations or 5 minutes)
Version Service creates immutable snapshot
Compressed and stored in S3:
Bucket: document-versions-{region}
Key: {doc_id}/versions/{version_id}/snapshot.gzDocument Service Updates
Updates metadata in PostgreSQL:
last_modified timestamp
document_size
revision_number
storage_locations (array of S3 URLs)
Invalidates cache entries
Publishes "document.saved" event to Kafka
Storage Optimization
Hot Storage (S3 Standard):
Current document version
Last 10 snapshots
Recent operation logs (7 days)
Warm Storage (S3 Standard-IA):
Snapshots 10-100
Operation logs 7-30 days
Cold Storage (S3 Glacier):
All snapshots > 100
Operation logs > 30 days
Compliance archives
Concurrent Save Handling
If multiple saves triggered simultaneously:
Distributed lock acquired (Redis Redlock)
Operations merged in order
Single write to S3 (prevents conflicts)
Lock released with TTL safety
Recovery Mechanisms
If S3 write fails:
Retry with exponential backoff
Fallback to backup region
Operations retained in Cassandra
Alert triggered after 3 failures
Data Flow for Document Recovery:
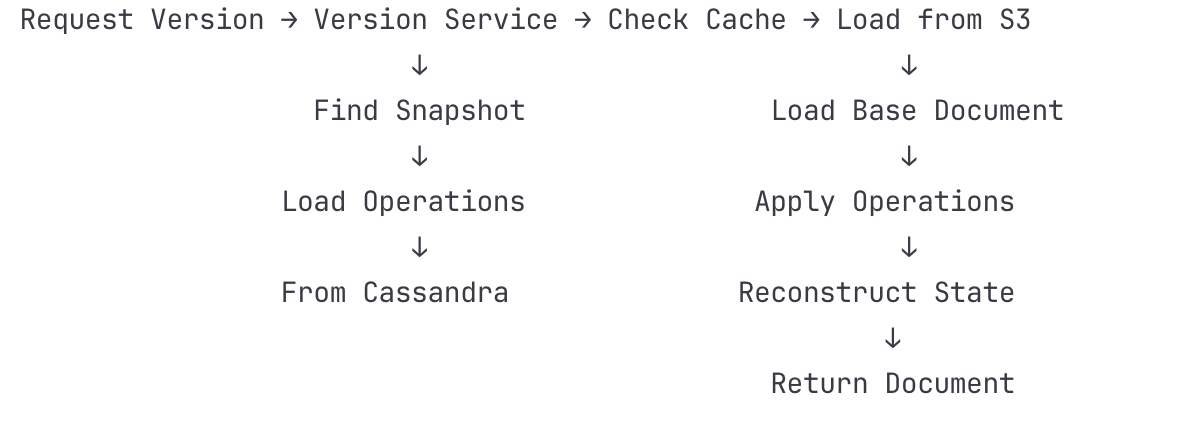
Tools & Technologies:
Object Storage: AWS S3 with lifecycle policies
Database: PostgreSQL for version metadata
Operation Log: Cassandra for high write throughput
Compression: Brotli for text compression
Cache: Redis for distributed locking
Flow 5: Offline to Online Synchronization

Detailed Steps:
Offline Editing
Network disconnection detected
Editor switches to offline mode
Operations stored in IndexedDB
Local version vector maintained
Local Storage Structure
javascript
{
document_id: "abc123",
offline_operations: [...],
last_known_revision: 156,
local_checksum: "sha256...",
offline_since: timestamp
}Network Recovery Detection
Periodic network check (every 5 seconds)
WebSocket reconnection attempted
Session restoration with server
Sync Service Initialization
Client sends sync request with:
Last known revision
Number of offline operations
Time range of offline period
Server-side Diff Calculation
Version Service retrieves operations since last_known_revision
Calculates operations client missed
Identifies potential conflicts
Three-way Merge Process
Base version: Last known common state
Local version: Client's current state
Remote version: Server's current state
CRDT or OT algorithm applied
Conflict Resolution
For each offline operation:
- Transform against server operations
- Check for semantic conflicts
- Apply resolution strategy:
- Text: Automatic merge
- Formatting: Last-write-wins
- Deletion: Requires confirmationSynchronization Execution
Server operations sent to client
Client operations sent to server
Both sides apply transformed operations
Checksum verification
Convergence Verification
Both sides calculate final checksum
If mismatch, full document sync
Update revision numbers
Clear offline storage
Tools & Technologies:
Client Storage: IndexedDB for offline data
Sync Protocol: Custom WebSocket protocol
Conflict Resolution: CRDT (Yjs) or OT engine
Compression: LZ4 for operation compression
Flow 6: Comment and Notification Flow

Detailed Steps:
User Adds Comment
Selects text range in document
Types comment with @mentions
Client sends POST to /api/comments
Comment Service Processing
Validates comment structure
Checks user has comment permission
Extracts mentioned users (@user parsing)
Stores in PostgreSQL
Comment Storage Schema
sql
comments_table:
- comment_id (UUID)
- document_id (FK)
- thread_id (for replies)
- user_id (FK)
- content (text)
- range_start, range_end
- created_at, resolved_at
- mentioned_users (array)Event Publishing
Comment Service publishes to Kafka:
Topic: "document.comment.created"
Payload: comment details + mentioned users
Notification Service Processing
Consumes event from Kafka
Identifies notification recipients:
Document owner
Mentioned users
Thread participants
Active collaborators (optional)
Notification Routing Logic
For each recipient:
- Check user preferences
- Check quiet hours
- Determine delivery channels:
- If online: WebSocket
- If mobile app: Push notification
- If offline > 5min: EmailMulti-channel Delivery
WebSocket (immediate):
Find user's WebSocket connection
Send notification packet
Update UI badge count
Push Notification (1-minute delay):
Retrieve device tokens from database
Format notification for platform (iOS/Android)
Send to FCM/APNS
Email (5-minute batch):
Queue in SQS/Pub/Sub
Batch multiple notifications
Render HTML template
Send via SendGrid/SES
Delivery Tracking
Log delivery attempts
Handle failures with retry
Update notification status
Track engagement metrics
Tools & Technologies:
Database: PostgreSQL for comments
Message Queue: Kafka for events, SQS for email
Push Services: FCM (Android), APNS (iOS)
Email Service: SendGrid or Amazon SES
WebSocket: Socket.io for real-time delivery
Flow 7: Document Sharing and Permission Update

Detailed Steps:
User Initiates Sharing
Clicks share button
Enters email/generates link
Selects permission level
Submits request
Permission Service Validation
Verify requester has 'can_share' permission
Validate recipient emails
Check organization policies
Apply security rules
Database Transaction
sql
BEGIN;
INSERT INTO permissions (doc_id, user_id, level, granted_by)
INSERT INTO sharing_log (doc_id, action, actor, timestamp)
UPDATE documents SET last_shared = NOW()
COMMIT;Cache Invalidation
Remove from Redis: permission:{doc_id}:*
Update user's accessible documents list
Broadcast cache invalidation to all regions
Notification Flow
Queue sharing notification
Generate secure invitation token
Send email with access link
Track invitation status
Tools & Technologies:
Database: PostgreSQL with transactions
Cache: Redis with pub/sub for invalidation
Email: Transactional email service
Security: JWT for invitation tokens
Performance Optimizations
Client-side Optimizations
Operational Transform Prediction: Apply operations optimistically
Lazy Loading: Load document in chunks as user scrolls
Virtual Scrolling: Render only visible portion of large documents
Debouncing: Batch rapid operations before sending
Compression: Use WebSocket compression for operation transfer
Server-side Optimizations
Operation Batching: Group operations for processing efficiency
Snapshot Strategy: Create snapshots every N operations
Delta Compression: Store only changes between versions
Connection Pooling: Reuse database and cache connections
Query Optimization: Denormalize frequently accessed data
Network Optimizations
Regional Deployments: Deploy services close to users
Anycast Routing: Route to nearest available server
Protocol Buffers: Binary serialization for efficiency
HTTP/3 with QUIC: Reduced connection establishment time
Multiplexing: Multiple operations over single connection
Security and Privacy
Authentication and Authorization
OAuth 2.0: Integration with Google accounts or enterprise SSO
JWT Tokens: Stateless authentication with refresh tokens
RBAC: Role-based access control with fine-grained permissions
API Keys: For programmatic access with rate limiting
Data Protection
Encryption at Rest: AES-256 for stored documents
Encryption in Transit: TLS 1.3 for all communications
End-to-End Encryption: Optional for sensitive documents
Data Residency: Compliance with regional data requirements
Security Features
Audit Logging: Complete trail of access and modifications
DLP Integration: Data loss prevention for enterprise
Malware Scanning: Automatic scanning of uploaded files
Version Control: Ability to restore after malicious changes
Monitoring and Observability
Key Metrics
System Metrics
Latency: P50, P95, P99 for all operations
Throughput: Operations per second, documents created/edited
Error Rates: 4xx, 5xx errors, failed operations
Saturation: CPU, memory, network, disk utilization
Business Metrics
Active Users: DAU, MAU, concurrent editors
Document Metrics: Creation rate, average size, collaboration rate
Feature Adoption: Usage of comments, suggestions, formatting
Performance: User-perceived latency, load times
Monitoring Infrastructure
Distributed Tracing: Jaeger or AWS X-Ray for request flow
Metrics Collection: Prometheus + Grafana or DataDog
Log Aggregation: ELK stack or Splunk
Real User Monitoring: Client-side performance tracking
Synthetic Monitoring: Automated testing of critical paths
Disaster Recovery and High Availability
Multi-Region Architecture
Active-Active: All regions serve traffic
Data Replication: Synchronous for metadata, asynchronous for content
Conflict Resolution: Last-write-wins with vector clocks
Failover: Automatic with health checking
Backup Strategy
Continuous Backup: Real-time replication to backup region
Point-in-Time Recovery: Snapshots every hour
Long-term Archive: Monthly backups to cold storage
Backup Testing: Regular restore drills
Failure Handling
Circuit Breakers: Prevent cascade failures
Retry Logic: Exponential backoff with jitter
Graceful Degradation: Reduced functionality over complete failure
Bulkheading: Isolate failures to prevent spread
Cost Optimization
Storage Optimization
Deduplication: Content-addressable storage for attachments
Compression: Document and operation compression
Tiered Storage: Hot-warm-cold based on access patterns
Retention Policies: Automatic cleanup of old versions
Compute Optimization
Auto-scaling: Scale based on actual demand
Spot Instances: For batch processing and non-critical workloads
Reserved Capacity: For predictable baseline load
Edge Computing: Process at edge to reduce central load
Network Optimization
CDN Usage: Serve static content from edge
Connection Reuse: Persistent connections for real-time
Data Compression: Reduce bandwidth usage
Regional Routing: Keep traffic within region when possible
Conclusion
Building a Google Docs-like system requires careful consideration of numerous architectural decisions, from the choice between OT and CRDT for conflict resolution to the database sharding strategy and caching layers. The system must balance consistency with availability, performance with cost, and simplicity with feature richness. Success depends on thoughtful design of each component, comprehensive monitoring, and continuous optimization based on real-world usage patterns. The architecture must be flexible enough to evolve with changing requirements while maintaining the reliability and performance users expect from a critical productivity tool.