

Pipelines, Platforms, Agents
The honest engineering view on the three eras of software delivery — and what “AI-native” actually means

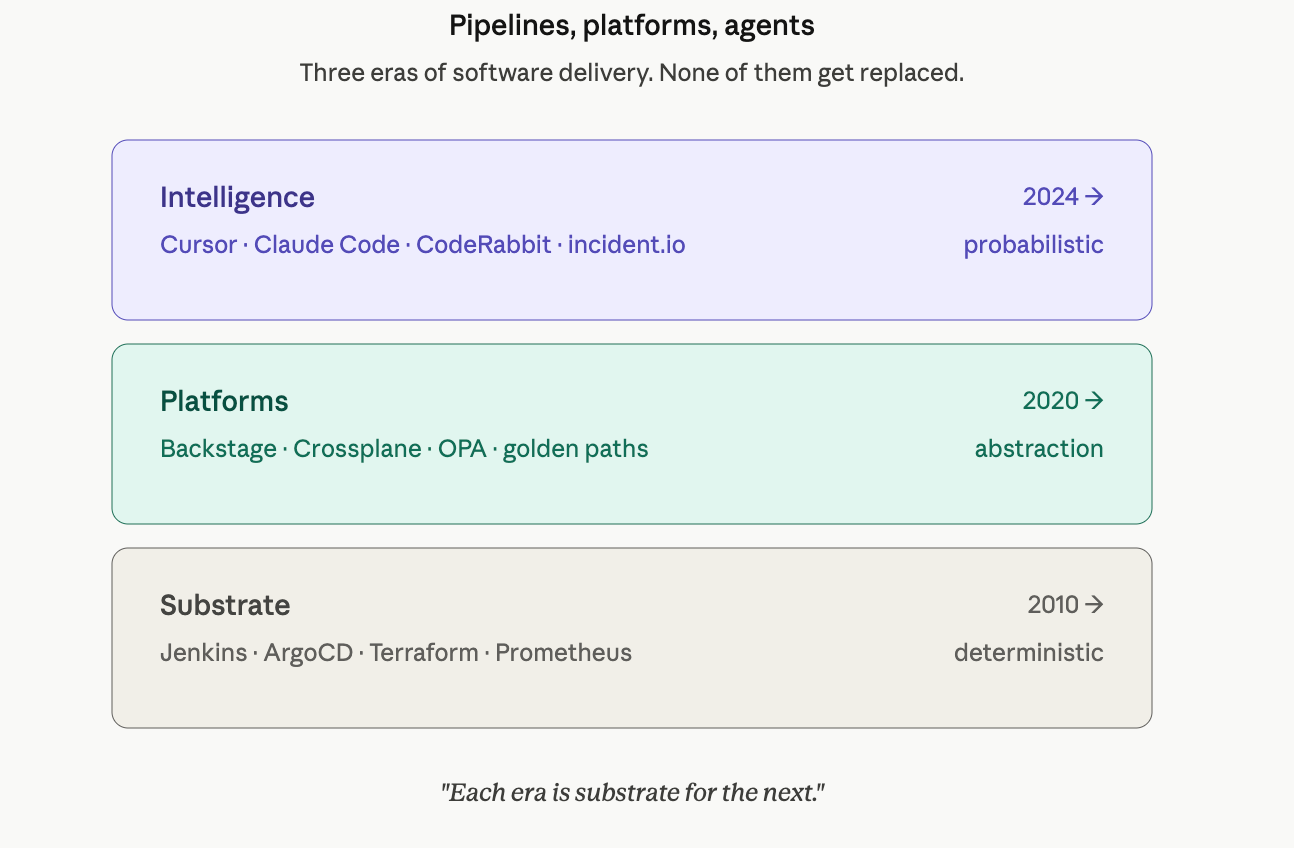
Software delivery has gone through three structural shifts in the last fifteen years, and each one solved the bottleneck the previous era had created.
The first shift gave us pipelines and replaced manual release theater with automation.
The second shift gave us platforms and replaced toolchain sprawl with developer abstractions.
The third — the one we’re living through right now — is layering probabilistic intelligence on top of both.
If you read the vendor pitches, you’d think this third shift is a clean break. “DevOps 2.0.” “AI-native delivery.” “Autonomous agents replacing static automation.” Most of that framing is wrong, or at least misleading. AI isn’t replacing CI/CD. It’s not replacing your platform. It’s not replacing your operators. What it’s doing is more interesting and more constrained: it’s becoming a new layer of judgment that sits above the deterministic substrate we’ve spent fifteen years building, and the teams that win will be the ones who understand the seam between those two layers.
This piece is the engineering version of that story. It’s written for product engineers who ship features for a living and want to understand what’s underneath the conveyor belt that takes their commits to production. It’s also written for tech leads and engineering managers who keep getting pitched “AI-native” platforms and want to know what’s real, what’s emerging, and what’s marketing. I’ll walk through the three eras, the bottlenecks each one resolved, the bottlenecks each one created, and where AI actually fits — not where the slide deck says it fits.
Era zero: the wall
To understand why we built any of this, you have to remember what software delivery looked like before it.
In the pre-DevOps world — call it roughly pre-2010 in most companies, later in regulated industries — software delivery was structurally adversarial. Developers were measured on shipping features. Operators were measured on system stability. These goals were locally rational and globally incompatible. Every release was a high-risk event because the people making the changes weren’t the people who lived with the consequences.
The mechanics looked like this. A development team would work for three to six months on a release. The release would get bundled into a tarball or installer, handed to QA for a multi-week regression cycle, then handed to operations for deployment during a maintenance window — usually a Friday night or weekend. A change advisory board would review every line item. Twelve people would dial into a bridge call. Someone would run scripts they’d written by hand, watch dashboards, and pray. If anything broke, the rollback was usually worse than the original problem because the deployment process wasn’t reversible — it was a one-way migration.
This system worked, in a sense, when software delivery was a low-frequency, high-stakes activity. Shrink-wrapped products. Banking core systems. Quarterly enterprise releases. The economics of release-as-event matched the economics of distribution.
But three forces broke that model in the late 2000s and early 2010s.
The first was the internet itself: software-as-a-service replaced shrink-wrapped software, which meant the deployment surface was now the vendor’s problem and the user expected continuous improvement, not annual upgrades.
The second was scale: companies running web-scale infrastructure couldn’t afford weekend deploys; their systems had to keep running while changing.
The third was distributed architectures: as monoliths broke into services, the number of deployable units exploded, and the human-coordination cost of release-as-event became combinatorial.
What we needed wasn’t a better release process. We needed to eliminate the release as a unit of work and replace it with a continuous flow of small, reversible changes. That was the actual problem DevOps was invented to solve.
Era one: DevOps 1.0 — automation as the unit of work
The DevOps movement gets remembered as a cultural revolution — “you build it, you run it,” shared ownership of production, the breaking of the dev/ops wall. All true. But culture without infrastructure is wishful thinking, and the technical scaffolding that made shared ownership possible is what actually changed how software gets built. Four pillars went up in roughly a decade.
Continuous integration
solved the merge-hell problem. Before CI, teams worked on long-lived branches and hit integration day at the end of a release cycle, when conflicts had compounded into a multi-week archaeology project. CI inverted the model: every commit triggers an automatic build and test run, and integration issues surface in minutes rather than weeks. Jenkins was the workhorse for the first generation; CircleCI, Travis, GitHub Actions, GitLab CI, and Buildkite followed with progressively more declarative models. The discipline shift was as important as the tooling: you committed small, you committed often, you kept main shippable, and the build became a non-negotiable contract.
Continuous delivery and deployment
automated the path from a green build to a running production system. This is where infrastructure-as-code starts to matter, where deployment strategies (blue/green, canary, rolling) get formalized, and where the idea of treating deployment configuration as versioned, reviewable artifacts replaces the older idea of deployment as an ops procedure. Spinnaker, Argo CD, Flux, Octopus, Harness — different flavors of the same thesis: the path to production should be a pipeline of automated steps with explicit promotion gates, not a runbook executed by a human at 11 PM on a Friday.
Infrastructure as code
moved infrastructure from clicked-through console state to versioned files. Terraform was the breakthrough — declarative, provider-agnostic, plan-and-apply semantics. Pulumi, CloudFormation, Bicep, and CDK followed with variations on the abstraction. The deeper shift was that environments became reproducible. You could destroy a staging environment and rebuild it in twenty minutes. You could review infrastructure changes in pull requests like application code. Drift between environments became a detectable, fixable problem rather than an invisible source of weekend incidents.
Observability
evolved from “tail the logs in /var/log” to a structured discipline of metrics, logs, and traces. Prometheus and Grafana became the OSS default for metrics. The ELK stack and later OpenSearch handled log aggregation. Distributed tracing — Zipkin, then Jaeger, then OpenTelemetry — gave you the ability to follow a request across service boundaries. Honeycomb introduced high-cardinality observability and the discipline of asking arbitrary questions of your production data. Datadog and New Relic packaged the whole stack into commercial products. The cultural shift was that production became legible in a way it hadn’t been before. You could ask, “what changed in the last hour and which services are affected?” and get an answer in seconds rather than days.
These four pillars worked together as a coherent system, and the results were measurable.
The DORA research program, which Nicole Forsgren and team formalized in Accelerate, gave us four metrics that became the industry yardstick: deployment frequency, lead time for changes, mean time to recovery, and change failure rate. Elite-performing teams went from quarterly releases to multi-deploy days, with lead times measured in hours and MTTR measured in minutes.
The economic argument was settled: organizations that adopted continuous delivery shipped faster and more reliably than those that didn’t. Not a tradeoff. A correlation.
For about a decade, this was the consensus stack. Every serious engineering team built some version of it. And then it started to break — not because the ideas were wrong, but because the second-order effects of the toolchain started to dominate.
Where DevOps 1.0 broke: the toolchain tax
The trouble with the four-pillar stack is that each pillar is best-of-breed from a different vendor or open-source project, and gluing them together became a full-time job that nobody had budgeted for.
A typical mid-sized engineering organization in 2022 was running something like this: GitHub or GitLab for source control, GitHub Actions or Jenkins for CI, Argo CD or Spinnaker for delivery, Terraform for cloud infrastructure, Helm for Kubernetes manifests, Vault or AWS Secrets Manager for secrets, Prometheus or Datadog for metrics, OpenSearch or Splunk for logs, Jaeger or Tempo for traces, Sentry for error tracking, PagerDuty for alerting, Snyk or Dependabot for dependency scanning, SonarQube for code quality, and Backstage for service cataloging. Twelve to fifteen tools, twelve to fifteen authentication surfaces, twelve to fifteen places where a pipeline could break, and twelve to fifteen vendor relationships to maintain.
The cost of this manifested in three ways, each of them quietly devastating to engineering velocity.
The first cost was cognitive load on developers. A backend engineer who wanted to ship a new service had to learn the company’s Terraform module conventions, Helm chart structure, Kubernetes RBAC, secret rotation procedures, observability emission standards, deployment strategy configurations, and on-call runbook formats. Most of this isn’t their job. It’s incidental complexity in the way of shipping features. The promise of “you build it, you run it” had quietly turned into “you build it, you also become a part-time platform engineer,” and developers started to push back. The pushback wasn’t usually loud — it showed up as services launching late, teams refusing to onboard to new infrastructure, and the spread of tribal knowledge that no one wrote down.
The second cost was snowflake pipelines. Every team built their own CI/CD with subtle variations. The Jenkinsfile in the payments service was different from the one in the search service was different from the one in the inventory service. Each one had its own custom steps, its own forked Helm charts, its own observability conventions. Senior engineers became “the YAML expert” — the person on the team who knew how to fix the build when it broke — and that role consumed thirty to forty percent of their time. Multiply that across an engineering org and you’ve spent a non-trivial percentage of your senior IC capacity on glue code.
The third cost was maintenance debt. The platform that was supposed to enable velocity became a velocity sink. Tool upgrades, plugin compatibility, drift between environments, security patches across the whole stack — all of it accreted. The Kubernetes upgrade that was supposed to take a week took a quarter because it touched fourteen tools. The CI provider’s new version deprecated a step that was used in eighty repos. The Datadog agent’s new sampling logic broke an alert that nobody noticed for a month. Every tool added to the stack added a maintenance vector, and the maintenance vectors compounded.
The cumulative effect was that DevOps 1.0, in its mature form, had inverted its own promise. The system that was supposed to reduce friction had become the friction. Developers spent more time fighting their pipelines than shipping features. Platform teams spent more time keeping tools alive than building leverage. The whole apparatus needed a refactor, not at the tool level, but at the abstraction level.
That refactor is what people are calling DevOps 2.0. The actual name for it — the one that’s stuck inside engineering organizations — is platform engineering.
Era two: platform engineering — abstractions as the unit of work
The thesis of platform engineering is simple, and once you see it, you can’t unsee it: most developers don’t want to use CI/CD, IaC, and observability primitives directly. They want to push code and have a paved road to production. So a platform team builds an abstraction layer — usually a self-service portal plus opinionated templates — that hides the underlying tools behind a simpler interface, and product engineers consume that abstraction without needing to know what’s underneath.
This is the same intellectual move that AWS made with cloud computing, that Stripe made with payments, that Twilio made with telephony. You take a category of incidental complexity, encapsulate it behind a clean API and a strong opinion, and let your customers go faster. The customers, in this case, are your own developers. The product is internal. But the discipline is the same.
The artifact this thesis produces is called an Internal Developer Platform, or IDP. The reference architecture has crystallized in the last few years and looks roughly like this.
At the front door is a service catalog, which is the single source of truth for every service in the organization. Backstage, the open-source project that Spotify donated to the CNCF, is the canonical implementation; commercial alternatives include Port, Cortex, and Atlassian’s Compass. The catalog tells you, for any given service, who owns it, what it depends on, what dashboards belong to it, what the on-call rotation looks like, and where the runbook lives. It replaces the seven-spreadsheet system that every company had been maintaining and pretending was a service inventory.
Behind the catalog are golden paths — opinionated templates for common service shapes. “Go HTTP service backed by Postgres.” “Python batch job triggered by SQS.” “Frontend app deployed to a CDN.” A developer scaffolds from a template and gets, in one motion, a repository with CI configured, deployment configured, monitoring configured, alerting configured, and on-call wired up. The template encodes the platform team’s accumulated wisdom about how things should be built, and the cost of “doing it the right way” drops to zero because the right way is the default. The friction asymmetry now favors the paved road.
Underneath the templates is a self-service infrastructure layer with guardrails. When a developer needs a database, a queue, a feature flag, or a new domain, they request it through the portal, and the platform provisions it via Terraform, Crossplane, or a similar declarative substrate. The provisioning is policy-controlled — Open Policy Agent (OPA) or HashiCorp Sentinel enforces guardrails like “no public S3 buckets,” “all databases must be in a private subnet,” “production resources require approval.” The platform team owns the guardrails. The product team owns the request. Nobody’s clicking through a console.
Across the whole stack runs a standardized observability and operations layer. Every service emits the same metrics conventions, the same log structure, the same trace headers. Every service has a default dashboard, a default set of SLO alerts, a default error budget. The platform team owns the conventions. The product team gets the visibility for free.
The intellectual lineage that frames this work is Team Topologies, by Matthew Skelton and Manuel Pais. The book defines four team types and their interaction patterns: stream-aligned teams (the product engineers, organized around a value stream), platform teams (build the IDP and treat it as a product), enabling teams (consult and uplevel other teams on hard problems), and complicated-subsystem teams (own deep expertise in a specific domain — search, ML infra, payments, video).
The model isn’t an org chart; it’s a way of thinking about cognitive load. Each team type has a specific cognitive load profile and a specific interaction mode with the other types. Platform teams reduce cognitive load on stream-aligned teams. Enabling teams temporarily augment cognitive capacity. Complicated-subsystem teams absorb cognitive load that no one else has the depth to handle.
Two framings from this world are worth internalizing if you’re going to operate inside it.
The first is that the platform is a product. This is not a metaphor. You measure the platform’s adoption, its time-to-first-deploy for a new service, its developer NPS, its churn rate from teams that try it and route around it. If product teams are bypassing your platform because it’s painful or limiting, that’s the same signal as a SaaS product losing users — and the right response is the same: talk to your users, find the friction, and ship a fix. Platform teams that don’t do product discovery on their own developers end up building infrastructure that nobody uses, which is the worst possible failure mode because the work is invisible to leadership until it’s too late.
The second is that cognitive load is the unit of design. The platform’s job is to reduce developer cognitive load to the minimum needed to ship their domain. If a backend engineer needs to understand EKS pod identity, IRSA roles, and the difference between cluster-internal and ingress traffic just to deploy a service, your abstraction has leaked. Every platform interface is a contract about what the developer needs to know, and a well-designed platform pushes that “needs to know” surface as small as it can go without taking away the escape hatches that experts need.
The mature DevOps 2.0 organization looks meaningfully different from a mature DevOps 1.0 organization, even though the underlying tools are mostly the same. In a 1.0 org, every team is a self-contained unit that owns its full delivery stack and the cognitive load that goes with it. In a 2.0 org, there’s a clear seam: the platform team owns the substrate, the product team owns the domain, and the interface between them is a self-service portal plus a set of golden paths. The substrate is invisible to product engineers most of the time, and that invisibility is the entire point.
This is where the industry sat by 2023. Then a different kind of layer started to land on top of the platform.
Era three? The AI layer — and why it’s not actually a third era
The pitch you’ll see from vendors right now is that AI is the third major shift in software delivery, on par with DevOps and platform engineering. The framing usually involves words like “autonomous,” “self-healing,” “agentic,” and “AI-native.” The implication is that pipelines and platforms are about to be replaced by AI agents that handle delivery end-to-end.
This framing is wrong, but the kernel of truth inside it is interesting. Let me argue both sides.
The framing is wrong because it treats AI as a replacement for the deterministic substrate, when in fact AI is a layer on top of the deterministic substrate. CI/CD pipelines are not going away. Infrastructure-as-code is not going away. Observability is not going away. These systems are the foundation that AI is being layered onto, not competing with. You cannot have an AI agent that “handles deployment” without a deterministic deployment system underneath that the agent can call. The agent is the controller; the pipeline is the actuator. Both have to exist.
Where the kernel of truth lives is that AI is changing the nature of the interface between humans and the delivery system. Tasks that used to require a human to write a YAML file, read a dashboard, or interpret a log line are increasingly being done by AI assistants — sometimes as suggestions, sometimes as autonomous actions inside a guardrail. This is a real shift, and over time it will compound, because as the AI layer gets more capable, the cognitive load on the human shrinks further. It’s a continuation of the platform engineering thesis, not a departure from it.
The honest engineering view is that AI shows up in software delivery at five distinct surfaces, and each surface has a different maturity, a different risk profile, and a different value proposition. Generalizing across them — “AI is transforming software delivery” — washes out the differences that actually matter.
Surface one: code authoring
This is the most mature surface and the one most engineers have first-hand experience with. GitHub Copilot, Cursor, Claude Code, Windsurf, Cody, and Continue are all variations on the same thesis: the IDE becomes an AI-collaborative environment where suggestions, completions, edits, and chat-driven refactors happen inline with the work.
The architectural divide in this space is worth understanding. On one side are editor-anchored tools like Cursor and Copilot, where the AI is a co-pilot inside an editing session — it has fast, cheap access to the open file and a limited context window of related files, and it optimizes for low-latency, high-frequency assistance. On the other side are agentic loop tools like Claude Code and Aider, where the AI runs as a longer-lived process that can read files, run tests, edit code, and re-plan based on outcomes — it optimizes for autonomy and task completion at the cost of latency and context cost.
The interesting failure mode in agentic coding tools is what I’ve called the uncertainty tax:
when the agent doesn’t know which file to edit, it speculatively reads many files, and each speculative read inflates the context, which inflates the cost, which sometimes inflates the agent’s confusion.
Retrieval becomes the hidden bottleneck. The teams that get the most out of these tools learn to scaffold the agent’s context — pointing it at the right files, providing architecture documents, and constraining the search space — and the teams that don’t end up frustrated with the tools’ apparent randomness.
The takeaway: code authoring is the surface where AI has already changed the shape of the day-to-day work for many engineers, but the value is uneven. It’s transformative for greenfield code, well-trodden patterns, and quick prototypes. It’s less reliable for large unfamiliar codebases, deeply specialized domains, and tasks that require holding many invariants in mind at once. Senior engineers who treat it as leverage gain disproportionately. Junior engineers who treat it as a substitute for understanding gain in the short term and pay later.
Surface two: code review
Tools like Greptile, CodeRabbit, Diamond, and Qodo read pull requests and surface bugs, style violations, missing tests, security issues, and architectural concerns. The product is an automated reviewer that comments on PRs alongside the human reviewers.
The value is real but bounded. These tools are good at catching obvious classes of issues — null pointer risks, missing error handling, dependency vulnerabilities, deviation from house style. They are weaker on judgment-heavy review: is this the right abstraction? Does this design fit the system’s evolution? Should this even exist? Those questions require context that the tool doesn’t have, and probably shouldn’t have, because the act of articulating that context to a reviewer is part of how teams build shared understanding.
The pragmatic frame is that AI code review is additive to humans, not a replacement. It catches the long tail of obvious issues so that human reviewers can focus on the hard ones. The teams that benefit the most use it as a first-pass filter and a forcing function for hygiene; the teams that misuse it treat it as a substitute for human review and end up shipping subtly broken code with green comments on it.
Surface three: test generation
Diffblue, Codium (now Qodo), Meta’s TestGen-LLM, and a handful of others generate test cases from existing code. The use case is clear: legacy code with low coverage, where writing tests by hand is tedious and the existing code is the spec.
This is genuinely useful for raising coverage on legacy systems — a category of work that was previously hard to justify and easy to defer. It’s less useful for designing test strategies for new code, because the harder problem there isn’t generating the tests; it’s deciding what to test, what the contract should be, and what edge cases matter. Those are design decisions, not generation decisions.
There’s a deeper issue with auto-generated tests that the marketing tends to glide over: tests generated from existing code encode the existing code’s behavior, including its bugs. If your function has an off-by-one error and you generate tests against it, the generated tests will assert the off-by-one behavior, and the tests will pin the bug in place. AI-generated tests are most valuable when paired with human review of what the tests are actually asserting.
Surface four: incident response and operations
This is where the “agent” framing actually fits the reality. Tools like incident.io’s AI features, Rootly, PagerDuty’s AIOps, and emerging products like Resolve.ai run agents that triage alerts, correlate signals across telemetry, draft incident summaries, and suggest mitigation steps. The deterministic version of this work — runbooks — has existed forever. The AI version reads logs, metrics, and recent deployments, then proposes hypotheses and actions.
The value is concentrated in two places: reducing mean-time-to-recovery on common incident patterns (where the AI can pattern-match against historical incidents and suggest the obvious fix), and reducing the toil of post-incident documentation (where the AI can draft a timeline from telemetry and Slack messages, leaving the human to review and correct).
The risk is over-trust. Agents that suggest mitigations can be confidently wrong, and a sleep-deprived on-call engineer at 3 AM is uniquely vulnerable to confidently-wrong suggestions. The teams that deploy these tools well treat the agent’s suggestions as hypotheses to verify, not actions to execute. The ones that don’t will eventually have an incident caused by the incident-response agent, and that will be a learning experience.
Surface five: pipeline orchestration and deployment risk
This is the least mature surface, and also the one where the long-term value will probably be largest. The thesis is that an AI agent looks at a PR’s diff, the blast radius of the affected services, the recent incident history, the current traffic patterns, and the canary signal, and decides things like canary rollout speed, rollback triggers, and deployment timing.
Most of what’s shipping today under this banner is rules-based logic with AI lipstick — change-failure-rate thresholds, simple anomaly detection on canary metrics, basic correlation between deploy events and error rates. The genuinely AI-native version, where an agent reasons about deployment risk in a way that’s better than a competent SRE, is mostly aspirational at the moment.
But it’s the surface where the platform value will eventually accrue, because deployment-risk reasoning is the layer above CI/CD that no one has owned well. Pipelines are deterministic; they do what you tell them. Risk reasoning is judgment; it requires holding many signals in mind. That’s exactly the kind of work where AI augmentation has the most leverage, and the platform teams that build this layer well will create durable advantage.
The architecture of an AI-augmented delivery system
Step back from the surface-by-surface view and look at the architecture as a whole. What does an AI-augmented delivery system actually look like as a system?
The clearest mental model is probabilistic intelligence on deterministic substrate. The substrate is your CI/CD pipelines, your IaC, your observability, your incident management. These are deterministic systems: same input, same output, fully auditable. The intelligence layer is your AI assistants, agents, and copilots. These are probabilistic: same input, plausibly different output, partially auditable at best.
The interesting design problem is the interface between the two layers. AI agents need to be able to read from the substrate (logs, metrics, deployment history, code) and act on the substrate (open PRs, trigger deployments, page humans). The interface is where governance lives, where guardrails live, where the auditability of the whole system is determined.
A well-architected AI-augmented system has several properties.
It has narrow action surfaces. The agent can take a small, well-defined set of actions, each with explicit guardrails and rollback paths. “Open a PR with proposed changes” is a narrow action surface; the human reviews and merges. “Deploy to production autonomously” is a wide action surface; very few systems are mature enough to grant this without serious blast-radius controls.
It has explicit context boundaries. The agent knows what it can read and what it cannot. It can see logs and metrics for the service it’s reasoning about, but not customer PII. It can read code in the repository, but not credentials in the secret store. The boundaries are enforced by the substrate, not by the agent’s good intentions.
It has deterministic logging of probabilistic decisions. Every action the agent takes is logged with the prompt, the model version, the retrieved context, and the resulting decision. You can replay a decision, audit it after the fact, and update the agent’s behavior with the audit in hand. This is the AI-native version of the audit trail that compliance teams require for any production system.
It has human-in-the-loop checkpoints at the right granularity. Some actions execute autonomously; some require approval. The line between them is drawn by blast radius, reversibility, and confidence. A code-review comment is autonomous. An autoscaling decision might be autonomous within a band and require approval outside it. A schema migration is almost never autonomous.
The teams that build these systems well treat AI as an interface technology, not a replacement technology. The substrate is still the substrate. The platform is still the platform. The AI changes how humans interact with both, and over time it absorbs more and more of the routine cognitive work — but the underlying systems don’t go away. They become the trusted ground truth that the AI layer reasons about.
The hard problems no one wants to talk about
The vendor pitch for AI-native delivery is uniformly optimistic. The engineering reality has four hard problems that don’t get enough airtime, and any organization that’s serious about adopting this stack has to confront all four.
Governance over non-deterministic outputs. Traditional CI/CD systems are auditable because they’re deterministic — same input, same output, traceable through the pipeline. AI agents make decisions that aren’t reproducible the same way. If an AI agent approves a deployment that breaks production, who owns the decision? The human who configured the agent? The vendor who built the model? The organization that didn’t catch the failure mode in evaluation?
You need new audit trails, prompt versioning, model versioning, and evaluation harnesses. Most organizations don’t have these primitives yet, and building them is a real cost — both in engineering time and in compliance overhead.
Data privacy in the SDLC. Sending source code, production logs, customer data, and incident transcripts to third-party LLMs creates a new exposure surface. The exposure is real, even with vendor commitments around data retention and training. On-prem and bring-your-own-model options — Anthropic’s API with VPC-peering, Azure OpenAI in a private deployment, self-hosted Llama or Mistral variants — help, but they add operational complexity and reduce capability. Engineering organizations that handle regulated data have to make explicit choices here, and the choices have real cost. The default of “send everything to the cheapest commercial LLM” is not safe for most production contexts.
Skill atrophy and knowledge ownership. This is the slow-moving problem and probably the most important. If junior engineers learn to ship via AI without understanding what’s underneath — concurrency models, query plans, distributed system invariants, the actual behavior of TCP under partition — the team’s bus factor degrades in a way that’s invisible until something hard breaks. The AI is competent at routine work and confidently wrong at novel work, and the team that’s lost the muscle to do the hard work without it is uniquely exposed when the AI hits its limits. This isn’t a reason to avoid AI. It’s a reason to be deliberate about how junior engineers grow inside an AI-augmented environment, and to invest in the kind of fundamentals work that doesn’t have an obvious quarterly ROI.
Cost economics. Inference at the scale of “every PR, every deploy, every alert, every incident” is non-trivial. The economics shift the buy-vs-build calculus on platform tools. A team that was happy to pay for a SaaS observability product at $X may balk at the AI-augmented version at $5X, especially when the AI value-add is uneven across surfaces. The cost discipline that mature platform teams apply to cloud spend — FinOps, unit economics, attribution — is going to apply to AI inference next, and the teams that haven’t built that muscle will be surprised by their own bills.
These four problems aren’t reasons to avoid the AI layer. They’re the agenda for the next three years of engineering leadership in this space. The teams that solve them will have durable advantages. The teams that pretend they don’t exist will learn the hard way.
What to actually do
Step back from the analysis and ask: if all of this is roughly correct, what should you be doing about it?
For an individual contributor, the play is to invest in fundamentals and treat AI as leverage. The engineers who get the most out of AI tooling are the ones who already understand the systems they’re working with, because they can evaluate the AI’s output and catch the confidently-wrong cases. The ones who use AI as a substitute for understanding ship faster in the short term and accumulate a debt that compounds. The strategic move is to use AI to accelerate work you understand and to be deliberate about doing some work without it, especially in the foundations of your domain.
For a tech lead, the play is to own the AI-substrate interface in your domain. If you’re a backend lead, that means deciding where AI fits in your service’s delivery path — which surfaces are high-value, which are too risky, which guardrails you need. It means setting team norms about where AI is encouraged, where it’s optional, and where it’s discouraged. It means measuring the impact, not assuming it.
For a platform team, the play is platform engineering is your moat, AI is a feature. The IDP you’ve built — golden paths, self-service infrastructure, standardized observability — is the substrate that AI gets layered onto. Teams that don’t have the substrate cannot use AI well, because the AI has nothing structured to reason about. Teams that have a strong substrate get disproportionate AI leverage. The strategic implication is that platform investment is a multiplier on AI investment, not a competitor to it.
For a CTO, the play is build governance frameworks now, not later. The cost of retrofitting governance onto a system that’s already shipping autonomous AI decisions is much higher than the cost of building it in from the start. The organizations that will look five years from now like they “got AI right” are the ones that, today, are quietly building the audit trails, the policy frameworks, the human-in-the-loop checkpoints, and the evaluation harnesses. None of this is glamorous. All of it is what separates a serious engineering organization from one that’s chasing the marketing pitch.
The maturity model that ties this together is straightforward. You start with deterministic operations — the four pillars of DevOps 1.0, which most organizations now have in some form. You build a platform abstraction over them — the IDP, the golden paths, the platform-as-product mindset of DevOps 2.0. Then you layer AI augmentation onto the platform — at the right surfaces, with the right guardrails, measured against the right outcomes. Each layer is a force multiplier on the next. Skipping a layer doesn’t work; AI-augmented chaos is still chaos, just faster.
Closing thesis
Software delivery’s evolution isn’t really about tools. It’s about reducing the distance between intent and production — between an engineer’s idea of what should happen and the system’s reality of what does happen.
In the pre-DevOps era, that distance was measured in months: from feature spec to running code, with a release process in between that was its own multi-week project. DevOps 1.0 collapsed that distance to days or hours by automating the path from commit to production. DevOps 2.0 collapsed the cognitive distance by giving developers paved roads instead of raw primitives. AI is collapsing the semantic distance — the gap between what the developer means and what the system needs to do — by absorbing more and more of the routine translation work into a probabilistic layer above the substrate.
Each era removed a class of friction that the previous era had revealed. Each era’s tools became the substrate for the next era’s leverage. The CI/CD pipelines we built in the 2010s are the deterministic ground truth that AI agents are now reasoning about. The platforms we built in the 2020s are the structured interface that makes AI augmentation tractable. None of it gets thrown away. All of it gets built on.
The teams that will look back on this period as a moment they got right are the ones that treat each era’s primitives as substrate for the next, not as competitors to be displaced. They’re the ones who keep building the deterministic foundation while layering the probabilistic intelligence. They’re the ones who remember that the goal isn’t pipelines, isn’t platforms, isn’t agents — the goal is to make the distance between an engineer’s intent and a production system’s behavior as small as the underlying physics allows.
That’s the actual story of software delivery’s evolution. The vendors will keep selling you eras and revolutions. The work, as always, is layered, additive, and quietly compounding.
If this resonated, the through-line of my recent writing has been this layered view of engineering systems — substrate, abstraction, intelligence, all stacked. I’d love to hear where this view holds and where it breaks for your team.