
Quality at Scale: How Google Keeps Bugs in Check Across Billions of Lines
From monorepos to test automation — uncover the secrets that make Google’s codebase resilient and reliable.


The GWS Wake-Up Call
In Google's early days, testing wasn’t a top priority. The culture leaned heavily on engineering brilliance—smart people writing smart code. For the most part, that worked. A few systems had integration tests in place, but widespread, structured testing was rare. It was a bit like the Wild West of software development.
One system in particular felt the pain of that approach: the Google Web Server (GWS). This core service powers Google Search, handling every user query and returning results in real-time. In short, it’s to Google what air traffic control is to an airport—absolutely essential.
By 2005, GWS had ballooned in complexity. As the system grew, productivity took a nosedive. Releases slowed, and bugs were slipping into production far too often. Developers started losing confidence in their changes. At one point, over 80% of production pushes were rolled back due to bugs that made it all the way to users. It was a critical turning point.
To get things back on track, the GWS tech lead made a bold decision: every piece of new code would require automated tests, and these tests would run continuously. This marked a cultural shift—from reactive firefighting to proactive, engineer-owned quality.
Testing in a World That Moves Fast
Modern software development looks nothing like the days of shrink-wrapped CD-ROMs. Today, apps are updated frequently—sometimes multiple times per day. And behind every one of those updates lies a codebase with massive complexity.
At Google, even a “simple” service may consist of millions of lines of code, depend on hundreds of libraries, and serve users on dozens of platforms—each with countless hardware, OS, and network configurations. Manual testing just can’t keep up.
Take Google Search, for example. Testing it thoroughly would mean verifying everything from web results to movie listings, flight searches, images, and more. That workload would need to be duplicated across every country, language, and device—while also ensuring compliance with accessibility standards and security best practices.
The only way to test at that scale, speed, and complexity is through automation.
The Shift Toward Engineer-Driven Automation
What began as a necessary fix for GWS evolved into a foundational principle at Google: testing is not a phase, it's a built-in part of engineering. Automated testing became embedded in the development workflow, ensuring that rapid iteration doesn't come at the expense of reliability.
This approach isn’t just about catching bugs—it's about building confidence. With tests running continuously, engineers can move fast without fear. New features ship faster. Quality stays high. And users stay happy.
Write, Run, React: The Core of Google's Testing Philosophy
At the heart of modern software testing lies a deceptively simple cycle: write tests, run tests, and react to failures.
Gone are the days when QA meant handing off a release to a room full of manual testers. Today, the engineers who build the systems also own their quality. Writing tests is no longer someone else’s job—it’s a fundamental part of software development. Even in organizations with dedicated QA teams, developer-written tests are the backbone of quality assurance.
This approach isn’t just philosophical—it’s practical. At the pace and complexity of modern development, there's simply no other way to keep up. Sharing the responsibility of writing and maintaining tests across the entire engineering organization ensures that testing scales alongside code.
But writing and running tests is only part of the equation. The real power of automation comes when teams actively respond to test failures. In large, fast-moving systems, tests are going to fail—it’s inevitable. What determines the effectiveness of a testing strategy is how quickly and seriously those failures are addressed.
Letting broken tests linger is a fast path to eroded confidence and ignored test results. But when teams fix failures within minutes, they isolate issues faster, maintain high trust in their test suites, and ultimately ship better, safer code.
At Google, this mindset is deeply embedded: treat every test failure as an opportunity to improve the system, and act on it immediately. That feedback loop—write, run, react—is what allows engineering velocity to coexist with software reliability at global scale.
The Long-Term Payoff: Benefits of Testing Code
Automated testing isn’t just a tool—it’s a strategy for building resilient, maintainable, and fast-moving software systems. At Google, the investment in writing tests early pays off across the entire lifecycle of a project. Here’s how:
1. Less Debugging, More Building
Well-tested code enters the system with fewer bugs—and stays that way. Most defects are caught before the code is even submitted, saving hours of frustrating debugging down the line.
At Google, code is not static. A single component may be modified dozens of times over its lifetime, often by other teams or even automated systems. Without a strong test suite, every change introduces risk. But when tests are in place, they act as a safety net. If a new change—or even a change in a dependency—breaks functionality, it’s caught and flagged instantly by the test infrastructure. In many cases, bad changes are automatically rolled back before they ever reach production.
2. Increased Confidence in Code Changes
Change is constant in software. But with solid test coverage, teams can adapt and evolve their systems with confidence. Every critical behavior is verified continuously, allowing for safe iteration.
This is especially powerful when refactoring. If a change preserves behavior, existing tests don’t need to change—which makes it clear the refactor is correct. That clarity encourages teams to improve code structure regularly without fear of breaking things.
3. Executable Documentation
Traditional documentation can be unreliable—often outdated, vague, or incomplete. But clear, focused tests can serve as a living, executable form of documentation.
Each test explains how the system behaves in a specific case. Want to understand what the code should do for a certain input? Look at the test. If the requirements change and break an existing test, you get an instant, visible signal that your documentation needs updating.
That said, tests only work well as documentation if they are kept clear, concise, and purpose-driven. Good test hygiene is essential.
4. Simplified Code Reviews
At Google, no code is submitted without at least one peer review. But reviews are smoother—and faster—when solid tests accompany the change.
Rather than mentally tracing every edge case through unfamiliar logic, reviewers can see the test outcomes for themselves. The tests demonstrate correctness, handle edge cases, and verify failure modes. This allows reviewers to focus on design and clarity, not correctness alone.
5. Better Design Through Testability
Writing tests forces developers to think about how code will be used and maintained. If it’s hard to test, it’s often because the code has too many responsibilities, is too tightly coupled, or hides logic behind complex dependencies.
Testable code is usually well-designed code: modular, focused, and easier to maintain. When you fix design issues early—because testing made them visible—you save yourself from rework and complexity later on.
6. Faster, Higher-Quality Releases
At Google, many large projects with hundreds of engineers release new versions to production every single day. This velocity is only possible with a robust test suite.
Automated testing enables fast, safe deployments by catching regressions early and continuously verifying correctness. Teams move quickly not because they skip testing—but because they automate it at every step.
Designing a Test Suite: How Google Thinks in Sizes and Scopes
Creating a high-quality test suite isn’t just about writing tests—it’s about writing the right kinds of tests. At Google, this process starts by thinking about two distinct dimensions of every test case: size and scope.
Scope refers to what the test is verifying—the code paths it exercises and the behavior it checks.
Size refers to how the test runs—the resources it consumes, how isolated it is, and how fast it executes.
While size and scope can be related, they serve different goals. A test can have a narrow or wide scope regardless of its size. What matters is aligning your tests with the goals of speed, determinism, and scalability.
Test Sizes at Google: Small, Medium, and Large
Rather than classifying tests by conventional labels like “unit” or “integration,” Google categorizes tests by their runtime characteristics: small, medium, and large. These categories are not just guidelines—they are enforced by Google’s testing infrastructure, which can restrict what a test is allowed to do based on its declared size.
Small Tests: Fast, Isolated, Deterministic
Small tests are the most constrained—and the most valuable. They are built to be fast, simple, and extremely reliable.
Constraints:
Must run in a single process (often a single thread).
No network or disk access allowed.
No blocking calls (e.g.,
sleep, file I/O).Must avoid external dependencies—use test doubles instead.
These restrictions might sound harsh, but they’re intentional. Small tests avoid the biggest sources of flakiness and slowness: threads, I/O, and external systems. As a result, they run at CPU speed, are highly deterministic, and scale beautifully.
A suite of small tests—especially at Google’s scale—can run hundreds or thousands of times per day. Keeping these tests reliable is critical. Even a few flaky tests can disrupt productivity across thousands of developers. That’s why Google strongly encourages writing small tests whenever possible, regardless of the scope of what is being tested.
Medium Tests: More Realism, More Responsibility
When small tests are too restrictive, medium tests are the next step. These tests can do more—but they require greater care.
Permissions:
Can use multiple processes and threads.
Can make network calls, but only to localhost.
Can access more complex infrastructure (e.g., spin up a local DB or UI server).
Medium tests are ideal when you want to simulate more realistic environments—for example, testing your application’s behavior with a real browser or interacting with an actual database on the local machine.
However, with greater flexibility comes greater risk of slowness and nondeterminism. Even localhost communication can introduce variability, and blocking calls can delay feedback loops. Engineers writing medium tests must be more thoughtful to maintain reliability.
Large Tests: Full-System, End-to-End, and Expensive
Large tests remove most restrictions. They can communicate across the network, run distributed systems, and simulate production-scale environments.
Capabilities:
Can span multiple machines.
Can interact with remote clusters or services.
Often validate full end-to-end workflows or legacy systems.
Because they depend on many moving parts—remote networks, machine states, system latency—large tests are the least reliable and the most resource-intensive. These are typically not run during normal development, but are reserved for critical checks during builds, releases, or nightly test runs.
At Google, large tests are isolated from faster tests to avoid slowing down the feedback loop for developers. They play a crucial role in validating configurations, catching issues that can’t be mocked, and verifying complex system integrations.
Test Scope: What Your Tests Should Actually Cover
While test size (small, medium, large) describes how a test runs, test scope describes what a test is validating—the breadth of the system or logic under examination.
At Google, we place strong emphasis on test size for speed and determinism, but scope is equally important in ensuring we’re testing the right things. Understanding test scope helps teams make informed decisions about where to test and how deeply.
Understanding Scope: Narrow to Broad
Narrow-scope tests (commonly referred to as unit tests) validate a specific, isolated piece of logic—like a single method or class. They are your first line of defense against bugs.
Medium-scope tests (typically integration tests) verify the interaction between a small number of components, such as a backend service talking to a database.
Broad-scope tests (often end-to-end, functional, or system tests) cover entire workflows involving multiple services, subsystems, or even external dependencies.
The key here is what’s being validated, not necessarily what code is being executed. A test for a single class may run other classes too, and that’s okay—especially at Google, where we prefer real dependencies when feasible over excessive use of mocks or fakes.
Size ≠ Scope
It’s easy to confuse scope with size, but they are not the same:
A narrow-scope test may still be medium-sized if it requires a complex runtime environment (e.g., a browser for UI testing).
A broad-scope test may be small-sized if it mocks all external dependencies and runs entirely in-process.
For example:
Testing a REST endpoint with mocked I/O might be small-sized but broad in scope.
Testing a date-picker component might require launching a headless browser, making it medium-sized, even though it covers only a single component.
This separation gives engineers the freedom to write focused, fast tests without overcommitting infrastructure resources.
The Ideal Mix: The Testing Pyramid
At Google, we follow a variation of Mike Cohn’s famous Test Pyramid to balance size and scope effectively:
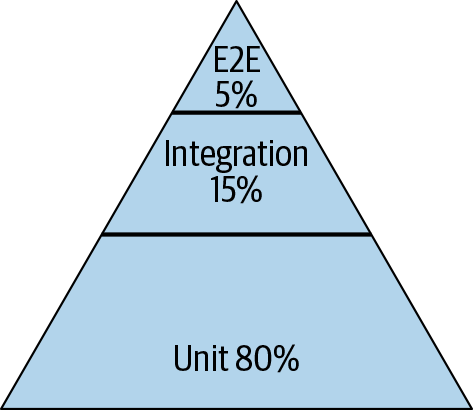
Unit tests form the foundation—they are fast, deterministic, and catch the majority of logic bugs.
Integration tests ensure components work well together, catching interface and contract mismatches early.
End-to-end tests act as sanity checks, validating full workflows before production rollout.
Avoiding Common Antipatterns
While the pyramid is ideal, many teams unintentionally fall into harmful testing shapes:

🍦 The Ice Cream Cone
Lots of end-to-end tests
Few or no unit or integration tests
Problem: Slow, flaky test suite. This happens when prototypes rush to production without testing infrastructure.
⌛ The Hourglass
Lots of unit tests and end-to-end tests
Few integration tests
Problem: Contracts between components go untested, and bugs that should be caught early get deferred to slower, more brittle tests.
Choosing the Right Scope for the Right Problem
Your own team’s pyramid may differ, and that’s okay. The right mix depends on:
The complexity of your architecture
The number of collaborating teams
The cost of test execution in your CI pipeline
Just remember:
Unit tests give you fast feedback and local confidence.
Integration tests help you verify assumptions between components.
End-to-end tests validate the big picture—but should never be your first or only line of defense.
A Note on Code Coverage: Useful Signal, Dangerous Goal
Code coverage is often treated as a litmus test for the quality of a test suite. On paper, it sounds simple: if your codebase has 100 lines and your tests execute 90 of them, you have 90% code coverage. That number feels concrete and actionable—but relying on it too much can be misleading, even harmful.
Why Code Coverage Isn’t Enough
Code coverage only tells you that a line of code was executed—not that it was verified.
You can reach 90% coverage with a few shallow tests that touch code paths without asserting any outcomes. For instance, a test might invoke a method that internally calls multiple classes, lighting up your coverage report like a Christmas tree—yet without checking that any of those classes actually did what they were supposed to do.
That’s why at Google, we recommend measuring coverage only from small tests—the ones that run in-process and are designed to verify specific logic. Larger tests (like integration or end-to-end) can inflate coverage metrics without adding meaningful validation.
The Trap of the Target
Code coverage becomes especially dangerous when it turns into a team-wide target. Say your team sets an 80% coverage requirement. Reasonable, right?
But here’s what often happens:
Engineers optimize to hit 80% and no more.
Testing becomes about satisfying the metric, not the system’s correctness.
Changes land with bare-minimum test coverage—not because the system is safe, but because the number says it's "enough."
In these situations, the metric becomes the goal, not the guide. And that’s where things start to fall apart.
Ask Better Questions
Instead of chasing an arbitrary number, ask more meaningful questions:
Do our tests validate the key behaviors our users rely on?
Are we confident that breaking changes would be caught before they reach production?
Are our tests reliable, fast, and diagnosable when they fail?
Are critical paths—such as login, payments, or data pipelines—well tested?
These questions focus your team on test effectiveness, not just test presence.
When to Use Code Coverage (and When Not To)
Code coverage isn’t useless—it can surface areas of the codebase that are surprisingly untested. But it should be a supporting tool, not a core KPI.
Use it to:
Identify accidental blind spots in your test suite.
Guide refactoring safety by ensuring unchanged lines remain exercised.
Encourage writing small, isolated tests that give you precise, confidence-building coverage.
But never use it as a substitute for critical thinking or thoughtful test planning.
Coverage Is a Clue, Not a Compass
Code coverage is just one input into your understanding of test quality. Like most metrics, it’s helpful when it prompts curiosity—but harmful when it becomes a quota. At Google, we don’t worship the number; we focus on writing tests that help us build safe, fast, and reliable systems.
Use code coverage wisely, and always ask: “Do my tests give me confidence?” If the answer is no, even 100% coverage won’t save you.
Testing at Google Scale: Lessons from a 2-Billion-Line Codebase
So far, we’ve explored testing fundamentals that apply to organizations of any size—test sizes, scopes, and the pitfalls of over-relying on code coverage. But what does testing look like when your engineering organization operates at Google scale?
To put things in perspective:
Google’s codebase consists of over two billion lines of code and undergoes 25 million lines of change every week. That’s not a typo.
This scale introduces unique challenges and shapes how testing, tooling, and collaboration are done.
One Monorepo to Rule Them All
Unlike many organizations that manage multiple repositories, Google operates a monolithic code repository (monorepo) that stores nearly all source code across products and services.
This approach comes with a key cultural side effect:
Code is shared. Ownership is shared. Responsibility is shared.
Any engineer, in principle, can browse or make changes to nearly any codebase—whether it’s core search infrastructure or an internal library they rely on. Of course, all changes are subject to reviews by the respective owners, but the model encourages co-ownership rather than siloed control.
This openness allows engineers to fix bugs or improve APIs directly, instead of waiting for a distant team to act. But it also means that many changes come from outside the owning team—which makes reliable, automated testing absolutely essential.
No Branches, No Stale Code
Another surprising fact:
Google rarely uses branches in development workflows. Almost all work is committed directly to the mainline (head) of the monorepo.
Why?
Because in Google’s world:
All builds are based on the last validated commit.
All dependencies are built from source, right from that commit.
Everyone sees and builds with the same code, instantly.
There’s no “integration branch” or “release branch” hiding old, untested code. This keeps the entire organization on the same page—and makes test automation and fast feedback loops absolutely non-negotiable.
The Engine Behind It All: TAP
Managing quality at this scale wouldn’t be possible without massive investment in continuous integration (CI) tooling.
At the heart of this is Google’s Test Automation Platform (TAP)—a CI system that:
Validates every change before it is committed.
Runs billions of test cases per week.
Orchestrates tens of thousands of builds daily.
Keeps the velocity high without compromising stability.
Think of TAP as a system that ensures that every change, no matter how small or massive, gets tested against the entire ecosystem it touches—and that the entire company keeps moving forward in sync.
Why It Works
Google’s scale isn’t just about size—it’s about structure:
A shared codebase that enforces collaboration and reduces duplicated effort.
A trunk-based development model that minimizes integration overhead.
A culture of testing and automation that builds quality in, instead of trying to inspect it in later.
This environment enables a level of agility that might seem counterintuitive at first: the larger the codebase, the more important it is to simplify collaboration and enforce standards through tooling—not process bottlenecks.
Introducing Project Health (pH): A Modern Take on Test Certified
As part of our ongoing focus on engineering productivity, one of internal teams recently introduced a tool called Project Health (pH)—a modern replacement for the legacy Test Certified program.
Project Health continuously monitors and reports on a wide range of metrics related to the health and quality of a project. These include:
Test coverage
Test latency
Build performance
And other critical indicators of engineering hygiene
Each project is assigned a pH score on a scale from 1 (worst) to 5 (best). A pH-1 score flags a project in need of immediate attention, often indicating serious issues with test quality, speed, or reliability.
One of the most powerful features of pH is that it’s automatically integrated into any project using our continuous build infrastructure. That means almost every active project at Google receives a pH score without requiring any manual configuration.
By surfacing real-time metrics and encouraging transparency, pH empowers teams to take ownership of their project’s health—making it easier to catch problems early and maintain high development velocity over time.
Final Thoughts
Not every team needs a monorepo or billions of tests, but the principles behind Google’s testing infrastructure are widely applicable:
Prioritize speed and determinism in your tests.
Build CI workflows that catch issues before they reach production.
Encourage shared ownership of quality across teams.
Invest in tooling, not just process, to scale engineering productivity.
Testing at Google scale isn’t just about brute force—it's about intelligent infrastructure, cultural discipline, and a deep commitment to engineering excellence.
References :