

The Hero Problem: Why Distributed Knowledge Builds More Resilient Systems
Complex systems don't fail because they lack heroes. They fail because they depend on them.

The question isn't whether your team has experts. It's whether your system could survive without them. If the answer is no, you have a knowledge architecture problem.
In organizations managing distributed systems, microservices, and socio-technical infrastructure, a familiar pattern emerges: a handful of engineers become the go-to experts. They’re the ones paged at 3 AM. They’re the ones who can navigate the gnarliest incidents with apparent ease. They accumulate context, tribal knowledge, and an intuitive feel for how the system behaves under stress.
These people are invaluable. They’re also a liability.
The presence of heroes signals a deeper structural problem: knowledge concentration. When critical understanding lives in a few heads rather than being distributed across a team, the system becomes brittle. Not because those individuals might leave (though that’s a risk), but because the architecture of understanding itself is fragile.
The Illusion of Heroic Efficiency
Heroes resolve incidents quickly. This creates a seductive feedback loop.
An alert fires. The hero gets paged. Within minutes, they’ve identified the root cause, applied a fix, and restored service. The incident is closed. Metrics look good. The team breathes easier.
But what actually happened?
The organization just reinforced its dependency. The hero accumulated more context. The gap between their mental model and everyone else’s widened. The next time something breaks, they’ll be paged again. The system didn’t become more resilient; it became more reliant.
Speed of resolution and reduction of future risk are not the same thing. Heroes optimize for the former while often undermining the latter.
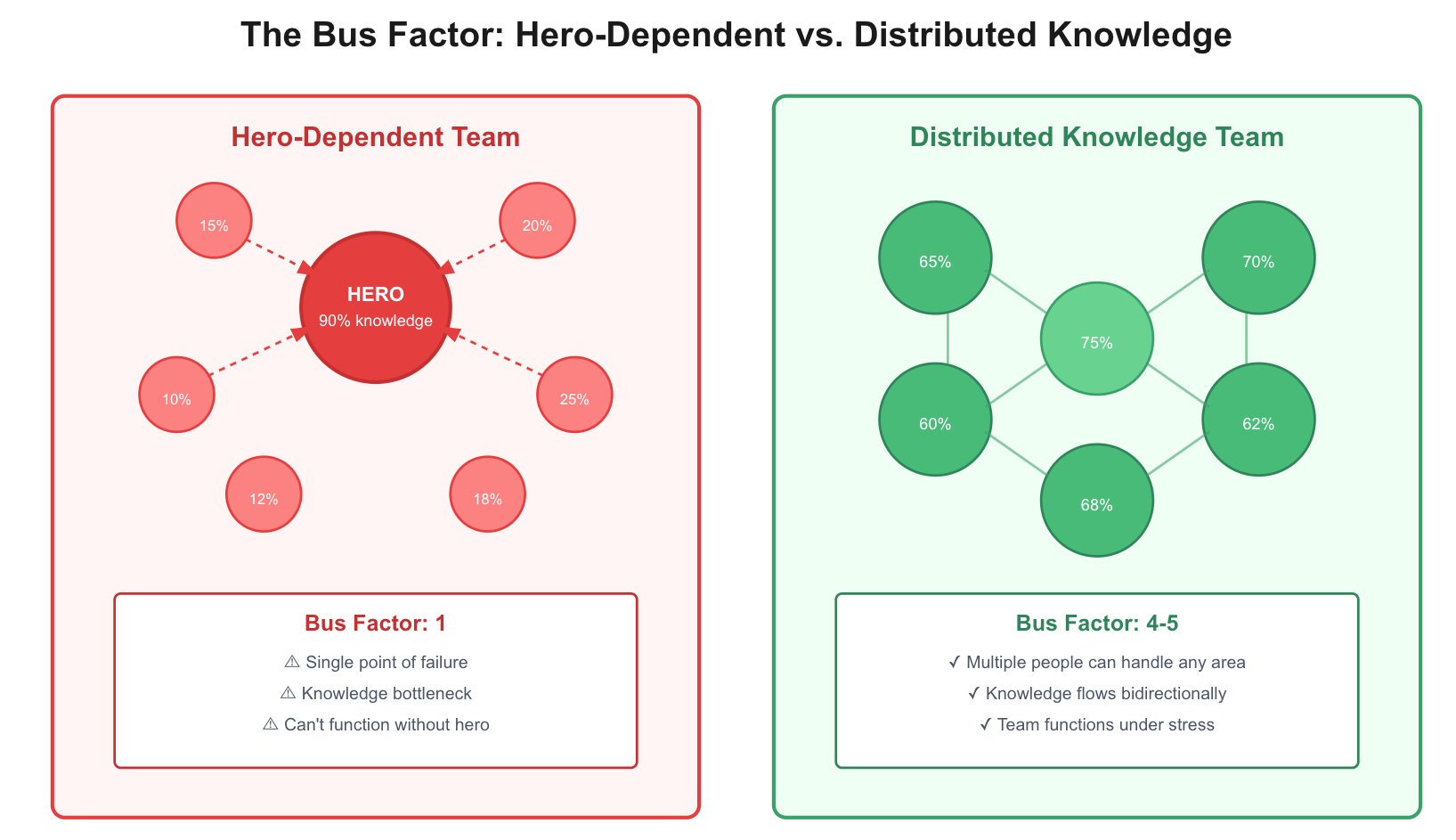
The Bus Factor and Beyond
The “bus factor” is the classic framing: how many team members need to be hit by a bus before the project grinds to a halt? It’s a useful thought experiment, but it understates the problem.
Even when heroes are present and available, concentrated knowledge creates bottlenecks:
Decision paralysis: Teams wait for heroes to weigh in before making changes
Review delays: Pull requests queue up because only certain people understand the implications
Cognitive overload: Heroes become overwhelmed trying to maintain their mental models as systems grow
Innovation drag: New ideas get filtered through a narrow set of perspectives
The issue isn’t just continuity if someone leaves. It’s the everyday friction of knowledge asymmetry.
Why Complex Systems Resist Individual Understanding
Modern distributed systems have outgrown individual comprehension. Consider what a single engineer would need to hold in their head:
Dozens of services with evolving interfaces and behaviors
Network topologies that shift as infrastructure scales
Dependency chains that span organizational boundaries
Failure modes that only emerge under specific combinations of load, latency, and state
Historical context about why certain decisions were made and what constraints they addressed
This isn’t a knowledge problem. It’s a complexity problem.
No single person can maintain an accurate, up-to-date mental model of a sufficiently complex system. Attempts to do so lead to approximations, outdated assumptions, and blind spots. The hero’s mental model is almost certainly incomplete or partially incorrect—but because they’re the expert, those gaps go unchallenged.
Shared Context as Infrastructure
If individual understanding is insufficient, the alternative is distributed cognition. Teams need to build shared context as deliberately as they build shared infrastructure.
This means creating systems for collective sense-making:
Incident reviews that prioritize learning over blame. The goal isn’t to identify who made a mistake, but to understand why the mistake was reasonable given the information available at the time. Good post-mortems surface gaps in shared understanding and become artifacts that distribute knowledge.
Documentation as a living practice. Not the static README that goes stale, but ongoing narrative work: decision logs, architecture decision records (ADRs), runbooks that evolve with the system. Documentation should capture not just what the system does, but why it does it that way.
Rotation and cross-training. On-call rotations force knowledge distribution. When different people investigate incidents, they develop complementary mental models. Pair programming and ensemble work accelerate this process.
Accessible observability. Metrics, logs, and traces should be comprehensible to the whole team, not just interpretable by experts. If only heroes can read the dashboards, the system’s legibility is broken.
Psychological safety for questions. Teams need norms where asking “why does this work this way?” is encouraged, not stigmatized. Naive questions often expose tacit assumptions that need to be made explicit.
The Performance Paradox
Organizations often resist distributing knowledge because it feels slower. Training new people takes time. Writing documentation takes time. Reviewing incidents thoroughly takes time.
But this is short-term thinking.
Concentrated knowledge creates linear scaling constraints. As the system grows, the hero becomes a bottleneck. Their capacity is finite. They can’t review every change, respond to every incident, or mentor every new engineer. The apparent efficiency of heroic knowledge is actually a ceiling on organizational capacity.
Distributed knowledge enables parallel work. When multiple people understand different parts of the system well enough to operate independently, the team’s effective capacity multiplies. More importantly, collective understanding improves under stress. When an incident occurs and the usual expert is unavailable, a team with shared context can still function. A team dependent on a hero cannot.
Failure Modes and Graceful Degradation
Complex systems fail in complex ways. Resilience comes not from preventing all failures, but from degrading gracefully when failures occur.
The same principle applies to teams.
A team with distributed knowledge can lose a member and continue operating. A team dependent on heroes experiences catastrophic failure when that person is unavailable—whether due to vacation, illness, departure, or simply being overwhelmed.
Consider two scenarios:
Scenario A: A critical service degrades on Saturday night. The expert is at a wedding with poor cell service. The on-call engineer, lacking sufficient context, makes a conservative decision: they roll back a recent deployment that might be related. Service is restored, but the actual cause—a resource leak triggered by a rare edge case—goes unidentified. It will happen again.
Scenario B: A critical service degrades on Saturday night. The expert is at a wedding with poor cell service. The on-call engineer has participated in several incident reviews, read the team’s decision logs, and spent time pairing with colleagues on this service. They check the same observability tooling everyone uses, recognize a pattern similar to a previous incident, identify the resource leak, and apply a targeted fix. The next week, they lead a retrospective that refines the team’s understanding of this failure mode.
The difference isn’t individual capability. It’s distributed knowledge.
From Heroes to Systems Thinking
Shifting from hero culture to distributed ownership requires treating knowledge as a system design problem.
Ask:
Where does knowledge currently concentrate, and why?
What mechanisms exist (or don’t exist) for knowledge sharing?
How do we make the system’s behavior more legible to everyone?
What incentives reward knowledge hoarding versus knowledge distribution?
Organizations often inadvertently create hero dynamics:
Rewarding individuals for firefighting rather than teams for prevention
Allowing documentation debt to accumulate unchecked
Treating on-call as a burden to be minimized rather than an opportunity to build understanding
Hiring for specialized expertise without investing in knowledge transfer
Changing this requires intentional counter-pressure: celebrating knowledge sharing, allocating time for learning, making system legibility a design requirement, and recognizing that in complex systems, the team’s collective understanding is the actual product.
The Long Game
Building distributed knowledge is slower at first. It requires investment. It means accepting that incident resolution might take longer when the usual expert isn’t driving. It means carving out time for activities that don’t ship features.
But resilience is a long-term property.
Teams that build shared context compound their capabilities over time. Each incident makes the team stronger, not just the individual who resolved it. New members onboard faster because knowledge isn’t trapped in conversations they weren’t part of. The system becomes more comprehensible, more maintainable, more adaptable.
Heroes burn out. Systems scale.
The goal isn’t to eliminate expertise. Deep knowledge will always be valuable. But when that knowledge remains concentrated rather than becoming distributed, it transforms from an asset into a vulnerability.
Complex systems require collective understanding. Not because individuals aren’t capable, but because the complexity itself exceeds individual capacity. The question isn’t whether your team has heroes. It’s whether your system could survive without them.
If the answer is no, you don’t have a resilient system. You have a fragile one wearing a hero’s cape